NEWS | October 27, 2020
NASA Funds Projects to Make Geosciences Data More Accessible
NASA has accumulated about 40 petabytes (PB) of Earth science data, which is about twice as much as all of the information stored by the Library of Congress. In the next five years, NASA’s data will grow up to 250 PB – more than six times larger than what NASA has now.
The sheer amount of data provided by NASA gives scientists and the public the extensive Earth science information they need for informed research and decision-making. But that amount of data creates a slew of challenges, including how to store the data, how to get it into consistent and useable formats, and how to search massive data sets.
To help address these issues, NASA has funded 11 new projects as part of the agency’s Earth Science Data Systems’ Advancing Collaborative Connections for Earth Systems Science (ACCESS) program. Proposals submitted in 2019 and funded in 2020 focused on three areas: machine learning, science in the cloud, and open source tools.
Earth scientists often work with data collected by NASA’s space, airborne, and ground observation missions. Before using all of that data for machine learning, however, they have to create large training datasets. For example, for machine learning to detect a forest in a new satellite image, the algorithm needs to be trained to detect forests. To do that, experts select and label forest areas in existing images and use that as the training dataset. Once the machine learning algorithm has been trained by looking at that dataset, the algorithm can distinguish forested areas in new satellite images.
Creating that training dataset can take months or even years – a problem that the geosciences community has dubbed the “training data bottleneck.” For their ACCESS project, David Roy from Michigan State University and his team are trying to expedite that process.
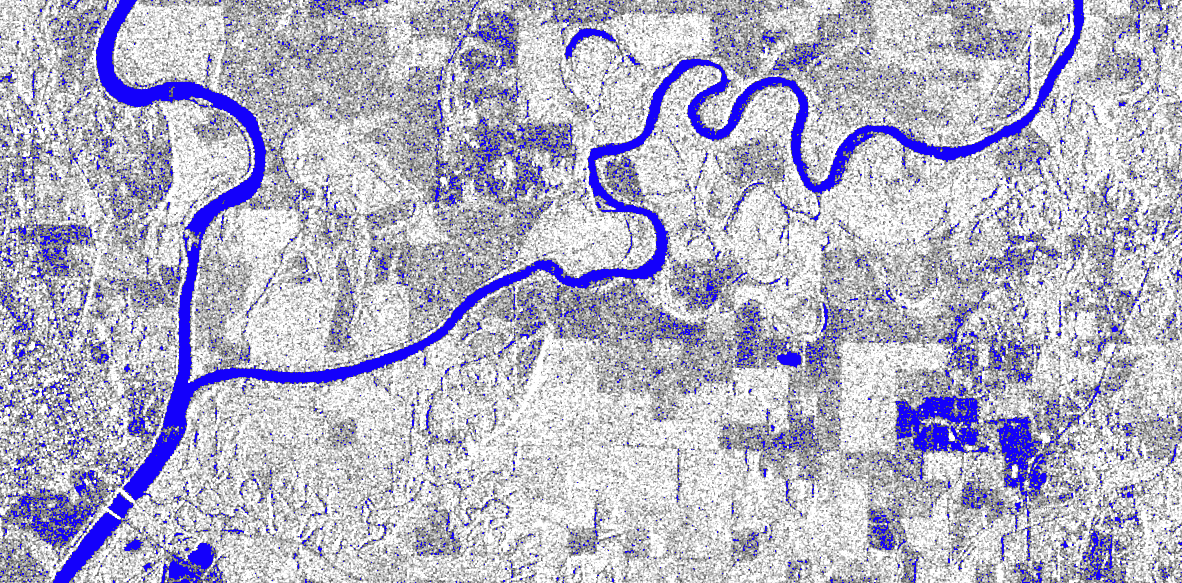
Roy’s project aims to create a high-quality, high-resolution training dataset that other scientists can use to quickly determine which areas are burned or covered with trees. The project is using high-resolution satellite data collected almost every day by Planet’s CubeSat constellation, acquired as part of NASA’s Commercial SmallSat Data Acquisition (CSDA) Program. Roy and his team will make the training dataset and software available through NASA’s ACCESS program so that other researchers can create their own training datasets.
Another 2019 ACCESS project – led by Fritz Policelli, a hydrologist at NASA’s Goddard Space Flight Center in Greenbelt, Maryland – focuses on machine learning with a different application. Policelli’s team is creating a high-quality training dataset of stream widths to help other scientists measure river width and streamflow around the world. These data track how much water is flowing through a river or stream over time, which has important applications for water resource management and monitoring floods.
Policelli’s work will complement the data collected by the Surface Water and Ocean Topography (SWOT) mission, scheduled to launch in late 2021. NASA and the Centre National D'Etudes Spatiales (CNES) are developing SWOT with contributions from the Canadian Space Agency (CSA) and United Kingdom Space Agency.
Among the data it collects, SWOT will measure stream flow rates around the world twice every 21 days. Policelli’s work will fill in the gaps between SWOT’s passes using stream width measurements from the European Space Agency’s (ESA) Sentinel-1 data and machine learning developed by his team.
Policelli’s team is partnering with NASA’s Alaska Satellite Facility Distributed Active Archive Center (ASF DAAC) at the Geophysical Institute at the University of Alaska, Fairbanks, which stores data collected by Sentinel-1 in the cloud. The new streamflow data will be stored, processed, analyzed, and distributed in that cloud, eliminating the problem of having to download massive data files. Prior to cloud storage and computing, geoscientists often had to plan their work schedules around waiting for large data files to download.
In addition to optimizing machine learning tools for geoscience research, Joe Hamman’s ACCESS funded project seeks to make those tools open source and easily accessible in the cloud. Hamman is the technology director at the San Francisco-based non-profit organization CarbonPlan. His project will create tools that bridge the gap between software used to analyze geoscience data and software used in machine learning. For example, converting geospatial data, which includes location information, to a format that can be used more effectively in machine learning. All of the tools developed will be open source to help researchers process data from many different sources, including the NASA-U.S. Geological Survey (USGS) Landsat fleet, the NASA-ESA Jason satellites, and the MODIS instrument aboard NASA’s Terra and Aqua satellites.
Eleven projects were selected for funding through the 2019 ACCESS program. All of the projects include some aspect improving machine learning, science in the cloud, or open science. See all of the 2019 projects here.
By Sofie Bates
NASA's Goddard Space Flight Center, Greenbelt, Md.